cto bench
Freemium
Dec 20, 2025
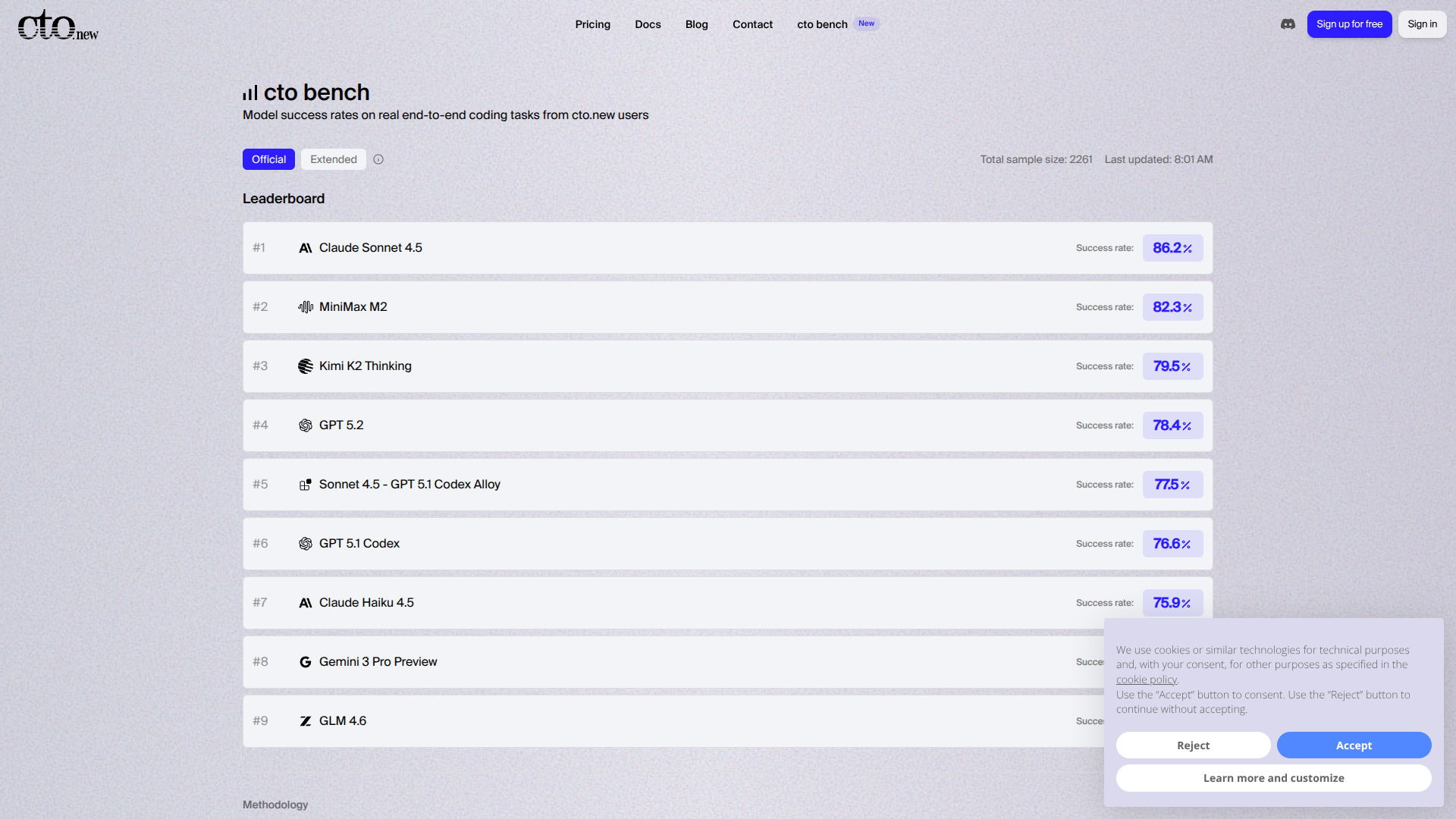
About cto bench
**O benchmark de agentes de código com verdade fundamental**
AI Summary
A maioria dos benchmarks de IA são construídos de trás para frente. Alguém senta, inventa problemas difíceis e então mede o quão bem os agentes os resolvem. Os resultados são interessantes, claro. Mas nem sempre te dizem o que importa: como os agentes se desempenham no trabalho real que está na sua fila. É por isso que construímos o cto.bench. Em vez de tarefas hipotéticas, estamos construindo nosso benchmark a partir de trabalho real. Cada ponto de dado no cto.bench vem diretamente de como os usuários do cto.new estão realmente usando nossa plataforma.
Detailed Description
Avalie IAs com o cto.bench! 🚀 Testes baseados em tarefas REAIS, não em problemas hipotéticos. Veja como IAs se saem no seu dia a dia, com dados diretos de usuários cto.new. Ideal para escolher a IA certa para o seu trabalho! ✅
Tool Screenshot

Click to enlarge
Key Features
Avalia o desempenho da IA com base em trabalho real.
Utiliza dados diretamente do uso real da plataforma cto.new.
Concentra-se em tarefas práticas em vez de problemas hipotéticos.
Oferece informações relevantes sobre como a IA lida com o trabalho real em fila.
Permite avaliar o desempenho da IA no contexto de uso cotidiano.
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools



Categories
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...

No comments yet
Be the first to share your thoughts and start the conversation!