DocBatch.ai
About DocBatch.ai
DocBatch.ai is an AI-powered batch document processing platform that automatically extracts structured data from PDFs and images at scale; you upload...
AI Summary
**DocBatch.ai: Extraia Dados de Documentos em Larga Escala com Inteligência Artificial**
Cansado de extrair manualmente dados de pilhas de PDFs e imagens? O DocBatch.ai é a solução! Esta plataforma de processamento de documentos em lote, impulsionada por inteligência artificial, automatiza a extração de dados estruturados, poupando tempo e minimizando erros. Basta fazer o upload dos seus documentos e o DocBatch.ai cuida do resto, identificando e extraindo informações relevantes de forma rápida e precisa.
Ideal para empresas que lidam com grandes volumes de documentos, como contratos, faturas, formulários e relatórios, o DocBatch.ai oferece escalabilidade e eficiência. Imagine automatizar a extração de dados de centenas ou milhares de documentos em questão de minutos!
Entre os principais benefícios, destacam-se a redução de custos operacionais, o aumento da produtividade e a melhoria da precisão dos dados. Com o DocBatch.ai, você pode focar em análises e decisões estratégicas, em vez de perder tempo com tarefas repetitivas e manuais. A plataforma é paga, mas o investimento se justifica pela economia de tempo e recursos que proporciona.
Cansado de extrair manualmente dados de pilhas de PDFs e imagens? O DocBatch.ai é a solução! Esta plataforma de processamento de documentos em lote, impulsionada por inteligência artificial, automatiza a extração de dados estruturados, poupando tempo e minimizando erros. Basta fazer o upload dos seus documentos e o DocBatch.ai cuida do resto, identificando e extraindo informações relevantes de forma rápida e precisa.
Ideal para empresas que lidam com grandes volumes de documentos, como contratos, faturas, formulários e relatórios, o DocBatch.ai oferece escalabilidade e eficiência. Imagine automatizar a extração de dados de centenas ou milhares de documentos em questão de minutos!
Entre os principais benefícios, destacam-se a redução de custos operacionais, o aumento da produtividade e a melhoria da precisão dos dados. Com o DocBatch.ai, você pode focar em análises e decisões estratégicas, em vez de perder tempo com tarefas repetitivas e manuais. A plataforma é paga, mas o investimento se justifica pela economia de tempo e recursos que proporciona.
Detailed Description
DocBatch.ai is an AI-powered batch document processing platform that automatically extracts structured data from PDFs and images at scale; you upload a sample, define fields via natural language or visual selection, and the system uses commercial AI models and deferred batch processing to run high-volume jobs via UI or API and return results in JSON/CSV/Excel with accuracy scores. Teams use it to automate invoices, receipts, contracts, forms and other repetitive document workflows to reduce manual labor and errors, cut processing costs significantly compared with real-time alternatives (often cited around 50% cheaper), and scale to thousands of pages while keeping data private and not using documents to train models.
Tool Screenshot
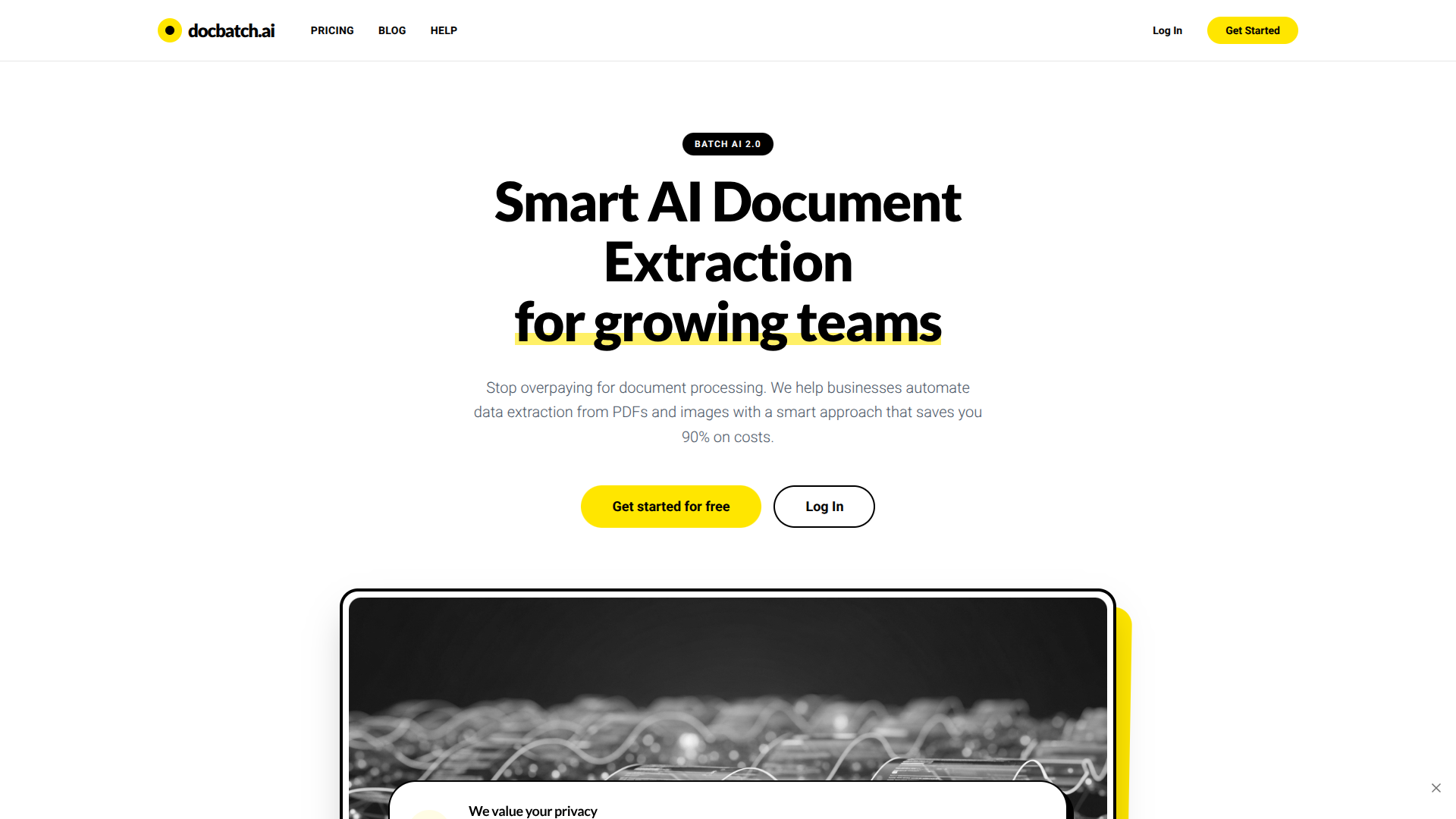
Click to enlarge
Key Features
Extração automatizada de dados estruturados de documentos
Processamento em lote de PDFs e imagens
Identificação e extração de informações relevantes
Escalabilidade para grandes volumes de documentos
Redução de custos operacionais
Aumento da produtividade
Melhoria da precisão dos dados
Tags
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools

Categories
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...
No comments yet
Be the first to share your thoughts and start the conversation!