Fallom
Freemium
Jan 23, 2026
Productivity
AI & Machine Learning
Developer Tools
Monitoring
Workflow Automation
AI
Business
AI Automation
Enterprise Software
AI, AI & Machine Learning, Business, Productivity, Developer Tools, Monitoring, AI Automation, Workflow Automation, Enterprise Software, AI Infrastructure, Observability
LLMOps
AI Observability
About Fallom
Fallom is an LLM observability platform that automatically traces every AI call—capturing prompts, inputs/outputs, tokens, latency, costs, and tool in...
AI Summary
**Fallom: A Visão Completa para Otimizar seus Modelos de Linguagem (LLMs)**
Cansado de navegar no escuro com seus modelos de linguagem? Fallom é uma plataforma de observabilidade para LLMs que ilumina cada interação, rastreando automaticamente todas as chamadas de IA. Imagine ter visibilidade total sobre seus prompts, entradas e saídas, número de tokens utilizados, latência, custos e até mesmo quais ferramentas foram acionadas.
Com Fallom, você consegue identificar gargalos de performance, otimizar seus prompts para reduzir custos e melhorar a precisão, e depurar problemas de forma eficiente. A plataforma captura dados cruciais para entender o comportamento dos seus modelos em produção, permitindo tomar decisões baseadas em dados e aprimorar continuamente suas aplicações de IA.
Ideal para desenvolvedores, engenheiros de machine learning e empresas que utilizam LLMs em larga escala, Fallom oferece uma camada de inteligência crucial para garantir o desempenho, a escalabilidade e o retorno sobre o investimento de suas iniciativas de IA. Com um modelo freemium, você pode começar a monitorar seus LLMs hoje mesmo e descobrir o poder da observabilidade.
Cansado de navegar no escuro com seus modelos de linguagem? Fallom é uma plataforma de observabilidade para LLMs que ilumina cada interação, rastreando automaticamente todas as chamadas de IA. Imagine ter visibilidade total sobre seus prompts, entradas e saídas, número de tokens utilizados, latência, custos e até mesmo quais ferramentas foram acionadas.
Com Fallom, você consegue identificar gargalos de performance, otimizar seus prompts para reduzir custos e melhorar a precisão, e depurar problemas de forma eficiente. A plataforma captura dados cruciais para entender o comportamento dos seus modelos em produção, permitindo tomar decisões baseadas em dados e aprimorar continuamente suas aplicações de IA.
Ideal para desenvolvedores, engenheiros de machine learning e empresas que utilizam LLMs em larga escala, Fallom oferece uma camada de inteligência crucial para garantir o desempenho, a escalabilidade e o retorno sobre o investimento de suas iniciativas de IA. Com um modelo freemium, você pode começar a monitorar seus LLMs hoje mesmo e descobrir o poder da observabilidade.
Detailed Description
Fallom is an LLM observability platform that automatically traces every AI call—capturing prompts, inputs/outputs, tokens, latency, costs, and tool invocations—and surfaces real-time dashboards, session/grouped traces, A/B model and prompt testing, built-in LLM evals, and full audit trails for compliance; its lightweight TypeScript/Python SDK (OpenTelemetry-native) wraps existing LLM clients in minutes so teams can monitor and debug AI agents, attribute cost, and safely roll out models across providers.
Tool Screenshot
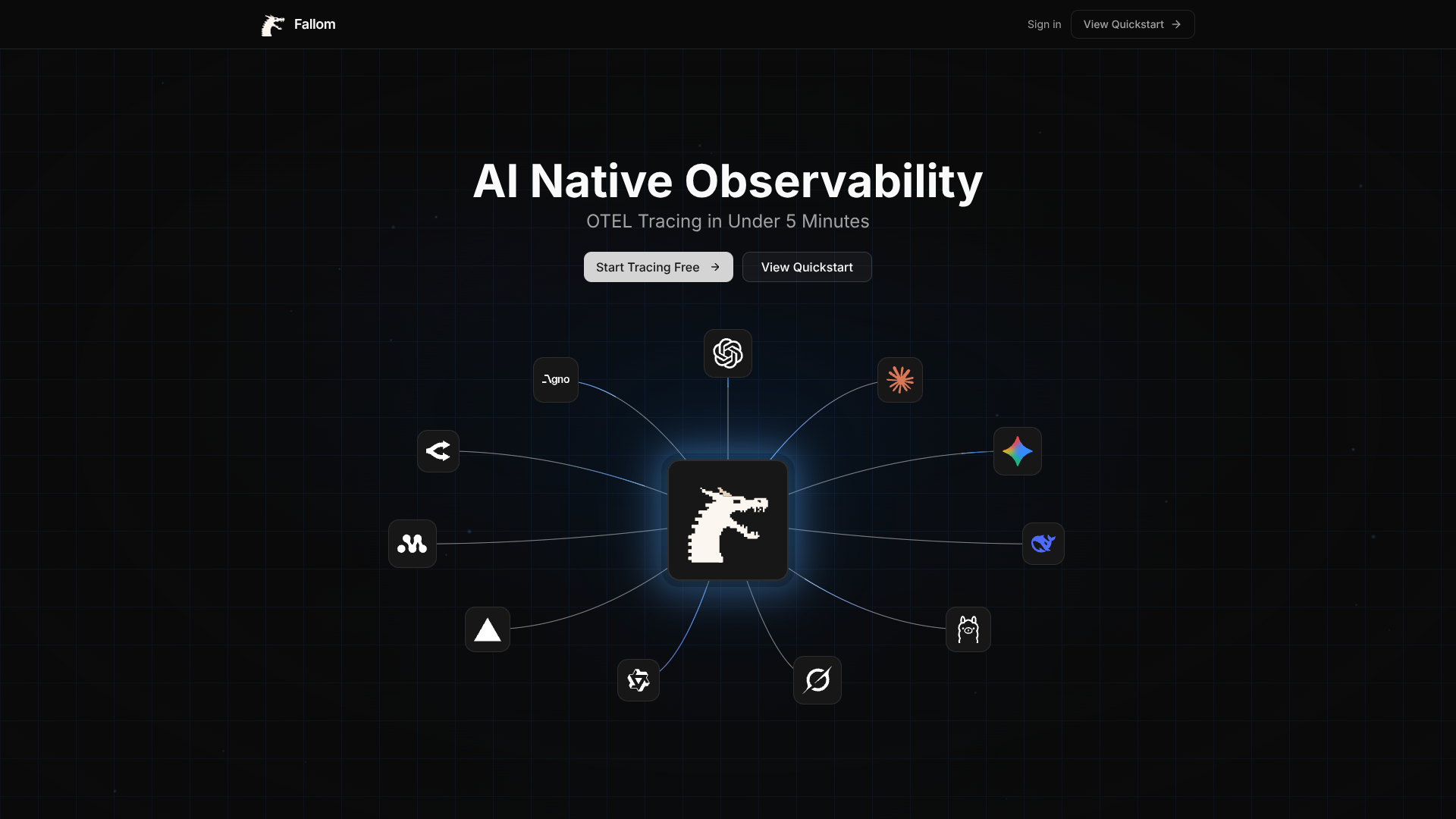
Click to enlarge
Key Features
Rastreamento automático de todas as chamadas de IA
Visibilidade completa sobre prompts, entradas e saídas
Monitoramento do número de tokens utilizados
Medição da latência
Acompanhamento de custos
Identificação de ferramentas acionadas
Identificação de gargalos de performance
Otimização de prompts para reduzir custos
Melhora da precisão dos modelos
Depuração eficiente de problemas
Captura de dados para entender o comportamento dos modelos em produção
Tomada de decisões baseadas em dados
Aprimoramento contínuo de aplicações de IA
Garantia do desempenho dos LLMs
Escalabilidade das aplicações de IA
Maximização do retorno sobre o investimento em IA
Tags
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools


Categories
Productivity
AI & Machine Learning
Developer Tools
Monitoring
Workflow Automation
AI
Business
AI Automation
Enterprise Software
AI, AI & Machine Learning, Business, Productivity, Developer Tools, Monitoring, AI Automation, Workflow Automation, Enterprise Software, AI Infrastructure, Observability
LLMOps
AI Observability
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...
No comments yet
Be the first to share your thoughts and start the conversation!