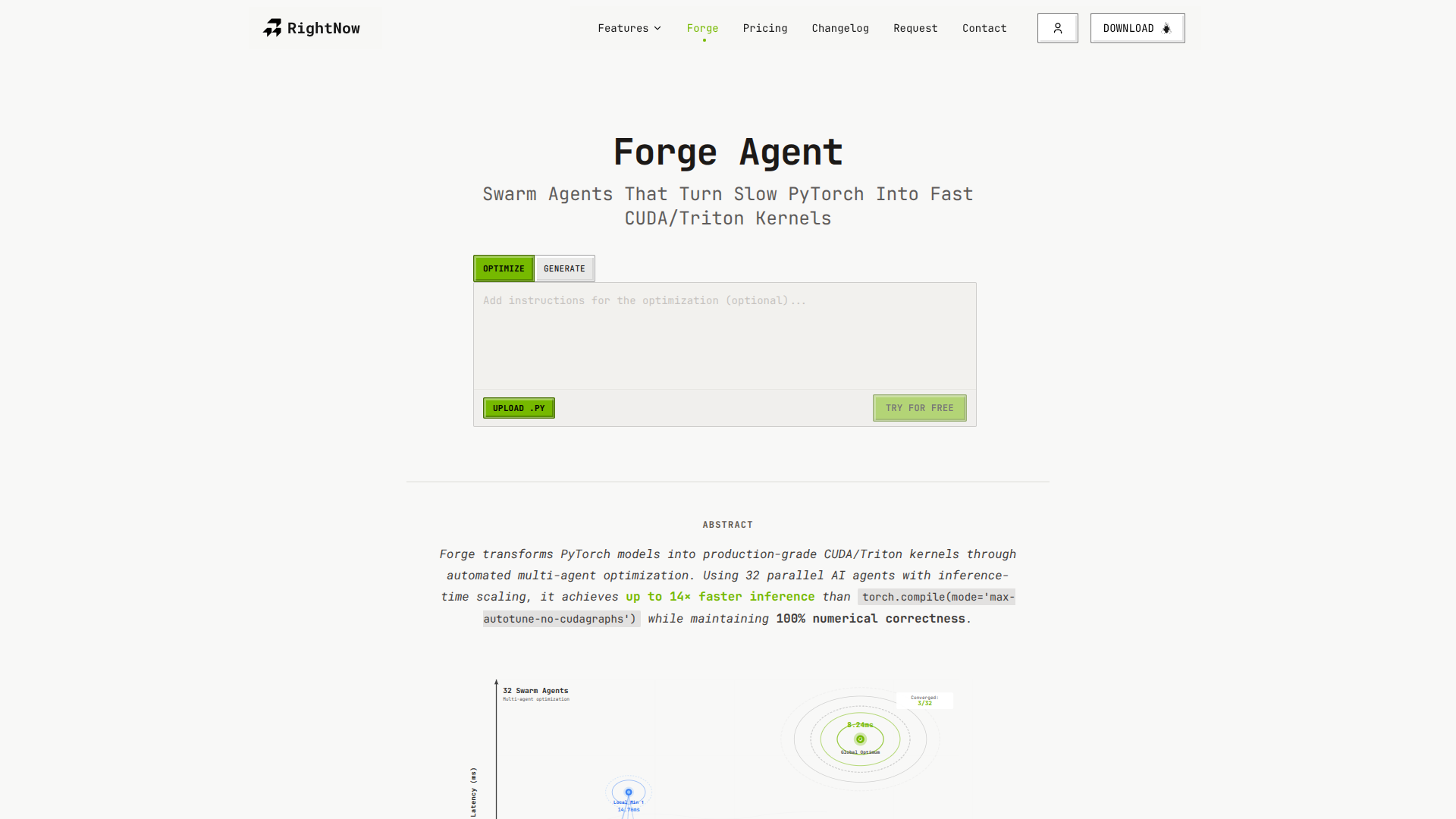
Forge Agent
About Forge Agent
**Agentes Swarm Que Transformam PyTorch Lento em Kernels de GPU Rápidos**
AI Summary
Forge transforma modelos PyTorch em kernels CUDA e Triton otimizados automaticamente. 32 agentes de IA rodam em paralelo, cada um testando diferentes estratégias de otimização como tensor cores, coalescência de memória e fusão de kernels. Um juiz valida cada kernel quanto à correção antes do benchmarking. Obtivemos inferência 5x mais rápida que torch.compile no Llama 3.1 8B e 4x no Qwen 2.5 7B. Funciona em qualquer modelo PyTorch. Teste gratuito em um kernel. Reembolso total se não superarmos o torch.compile.
Detailed Description
🚀 Forge: turbina seus modelos PyTorch! Transforma-os em kernels CUDA/Triton otimizados automaticamente. 32 agentes de IA testam estratégias (tensor cores, etc.). ✅ Validação rigorosa. Resultados? Até 5x mais rápido que `torch.compile` (Llama 3.1 8B) e 4x (Qwen 2.5 7B)! 🤯 Funciona com qualquer modelo PyTorch. Teste grátis! 💰 Reembolso total se não superar `torch.compile`.
Tool Screenshot

Click to enlarge
Key Features
Transforma modelos PyTorch em kernels CUDA e Triton otimizados automaticamente.
Utiliza 32 agentes de IA em paralelo para explorar diferentes estratégias de otimização.
Emprega estratégias como tensor cores, coalescência de memória e fusão de kernels.
Valida a correção de cada kernel antes de realizar o benchmarking.
Oferece inferência até 5x mais rápida que torch.compile em Llama 3.1 8B.
Oferece inferência até 4x mais rápida que torch.compile em Qwen 2.5 7B.
Funciona com qualquer modelo PyTorch.
Disponibiliza teste gratuito em um kernel.
Garante reembolso total se não superar o torch.compile.
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools


Categories
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...

No comments yet
Be the first to share your thoughts and start the conversation!