SelfHostLLM
Freemium
Aug 08, 2025
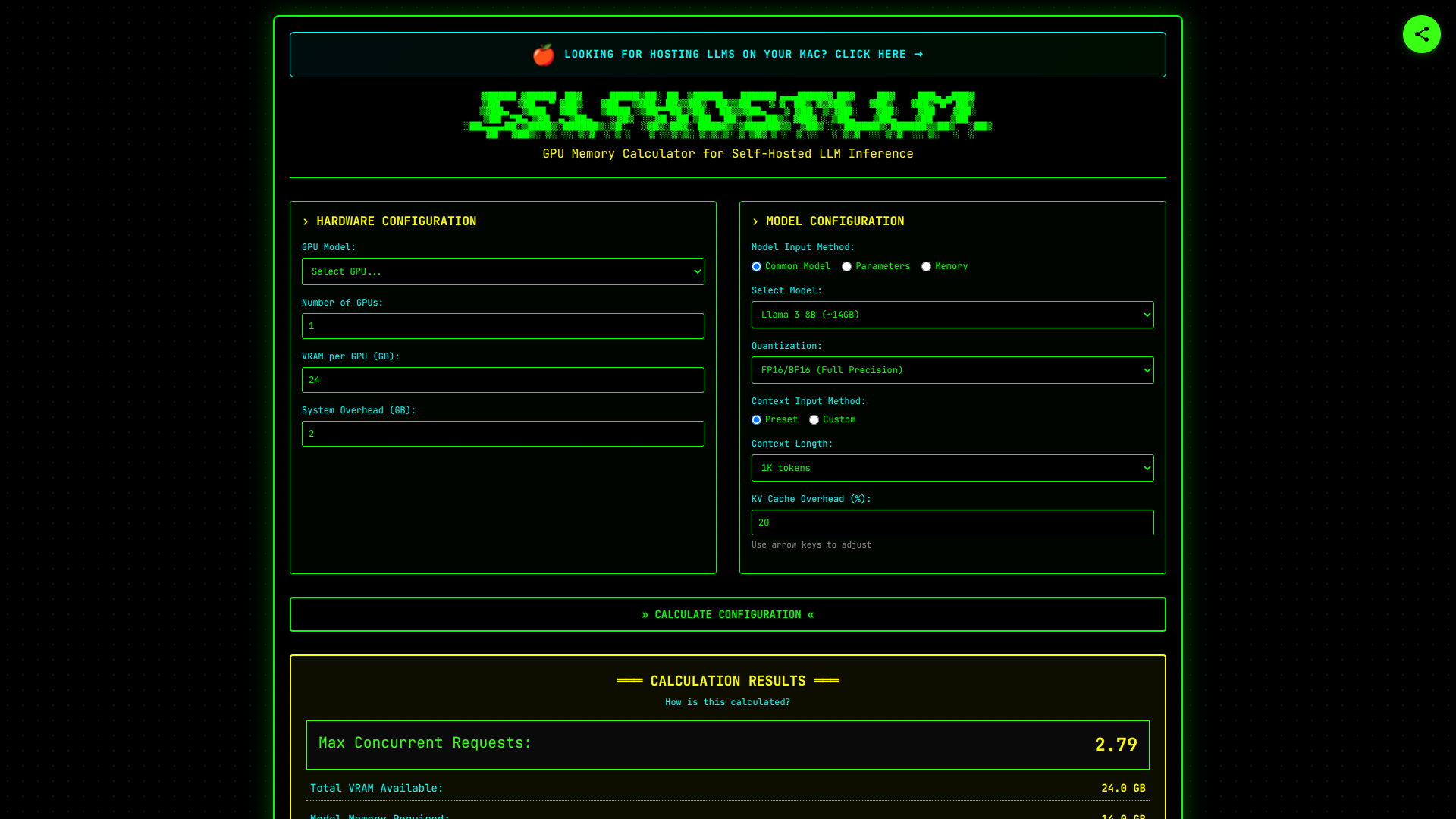
About SelfHostLLM
Calcule a memória da GPU que você precisa para inferência de LLMs
AI Summary
Calcule os requisitos de memória da GPU e o número máximo de requisições simultâneas para inferência de LLM auto-hospedada. Suporte para Llama, Qwen, DeepSeek, Mistral e muito mais. Planeje sua infraestrutura de IA de forma eficiente.
Detailed Description
Planeje sua infraestrutura de IA com precisão! 🧠 Calcule requisitos de memória GPU e requests simultâneos máximos para inferência de LLMs (Llama, Qwen, Mistral & +). Otimize seus custos e garanta performance! 🚀 Ideal para self-hosting e deployments eficientes. 💰
Tool Screenshot

Click to enlarge
Key Features
Calcular os requisitos de memória da GPU.
Determinar o número máximo de requisições concorrentes para inferência de LLM auto-hospedados.
Suporte para modelos Llama, Qwen, DeepSeek, Mistral e outros.
Planejar a infraestrutura de IA de forma eficiente.
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...

No comments yet
Be the first to share your thoughts and start the conversation!