TwelveLabs Marengo 3.0
Freemium
Dec 01, 2025
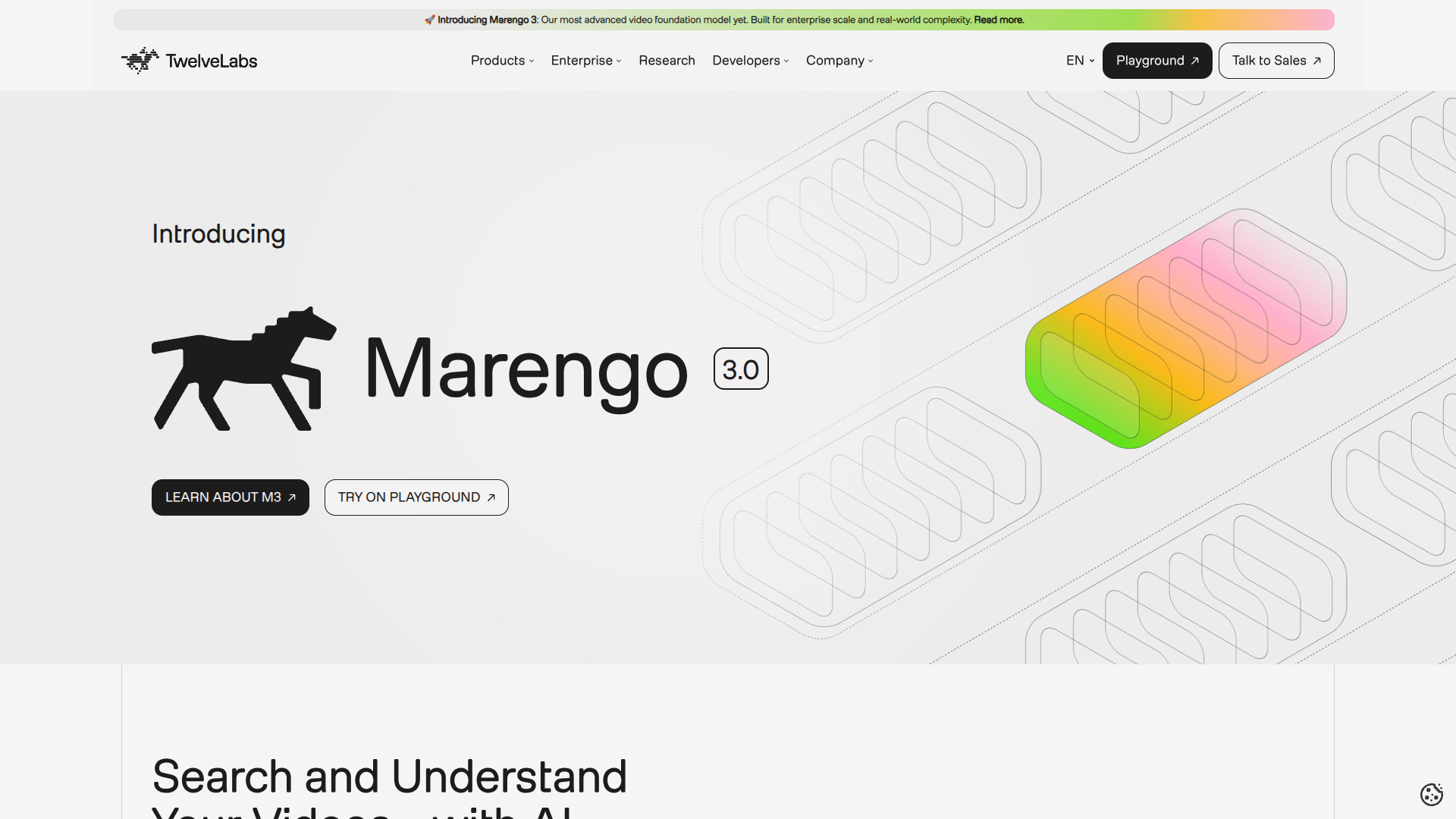
About TwelveLabs Marengo 3.0
O modelo de embedding mais poderoso para compreensão de vídeo
AI Summary
Marengo 3.0 é o modelo mais significativo da TwelveLabs até o momento, oferecendo compreensão de vídeo quase humana em escala. Um modelo de embedding multimodal, Marengo funde vídeo, áudio e texto para uma compreensão holística de vídeo, impulsionando a busca e recuperação de vídeo precisas.
Detailed Description
Marengo 3.0 da TwelveLabs: IA que entende vídeos como humanos! 🤯 Combina vídeo, áudio e texto para busca e recuperação precisas. 🔎 Encontre o que precisa em vídeos com facilidade! 🚀 Ideal para análise, organização e descoberta de conteúdo. ✨
Tool Screenshot

Click to enlarge
Key Features
Entendimento de vídeo em escala comparável ao humano.
Modelo de incorporação multimodal que combina vídeo, áudio e texto.
Entendimento holístico de vídeo.
Capacitação de busca e recuperação de vídeo precisas.
Comments 0
Join the conversation
Sign in to leave a comment and share your thoughts.
Related Tools
Categories
Discover More AI Tools
Explore our comprehensive collection of AI tools.
Browse AllReviews
Loading...
Loading reviews...

No comments yet
Be the first to share your thoughts and start the conversation!